
Algorithm
62. 不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。 问总共有多少条不同的路径?
例如,上图是一个7 x 3 的网格。有多少可能的路径?
说明:m 和 n 的值均不超过 100。
示例 1:
输入: m = 3, n = 2
输出: 3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
1. 向右 -> 向右 -> 向下
2. 向右 -> 向下 -> 向右
3. 向下 -> 向右 -> 向右
示例 2:
输入: m = 7, n = 3
输出: 28
解决方案:
我的解法:
class Solution {
public int uniquePaths(int m, int n) {
int[][] paths = new int[m][n];
for (int i = 0; i < m; i++){
paths[i][0] = 1;
}
for (int j = 0; j < n; j++){
paths[0][j] = 1;
}
for (int i = 1; i < m; i++){
for (int j = 1; j < n; j++){
paths[i][j] = paths[i - 1][j] + paths[i][j - 1];
}
}
return paths[m - 1][n - 1];
}
}
最高效解法:
class Solution {
public int uniquePaths(int m, int n) {
int [][]opt=new int[m+1][n+1];
for(int i=m-1;i>=0;i--){opt[i][n-1]=1;}
for(int j=n-1;j>=0;j--){opt[m-1][j]=1;}
for(int i=m-2;i>=0;i--){
for(int j=n-2;j>=0;j--){
opt[i][j]=opt[i+1][j]+opt[i][j+1];
}
}
return opt[0][0];
}
}
Review
这边文章介绍了提取富数据服务的方法和套路,形成了服务抽取模式。
服务抽取模式
服务提取指导原则
两条关键原则:
- 原则1:在整个转换过程中为数据创建一个写入副本。 拥有多个写拷贝会在多客户端写入时产生冲突。
- 原则2:遵循“架构演进的原子步骤”原则。 该原则强调服务的抽取一定要遵循架构演进的原子步骤,如若违反则可能会使得架构更加混乱。
服务抽取步骤
步骤1.识别与新服务相关的逻辑和数据 步骤2.为单体架构中的新服务的逻辑创建逻辑分离 步骤3.创建新表以支持单体架构中新服务的逻辑 步骤4.构建新服务指向单体架构数据库中的表 步骤5.将客户端指向新服务 步骤6.为新服务创建数据库 步骤7.将单体架构中的数据同步到新数据库 步骤8.将新服务指向新数据库 步骤9.在单体架构中删除与新服务相关的逻辑和schema
示例
在一个目录系统中其核心产品表中包含了价格,这两者的变化方向和频率是不一样的,因此有必要对价格相关的内容进行抽取。价格在整个系统中属于“叶子”依赖,因此价格功能是提取的首选目标。
目录服务的逻辑和数据:
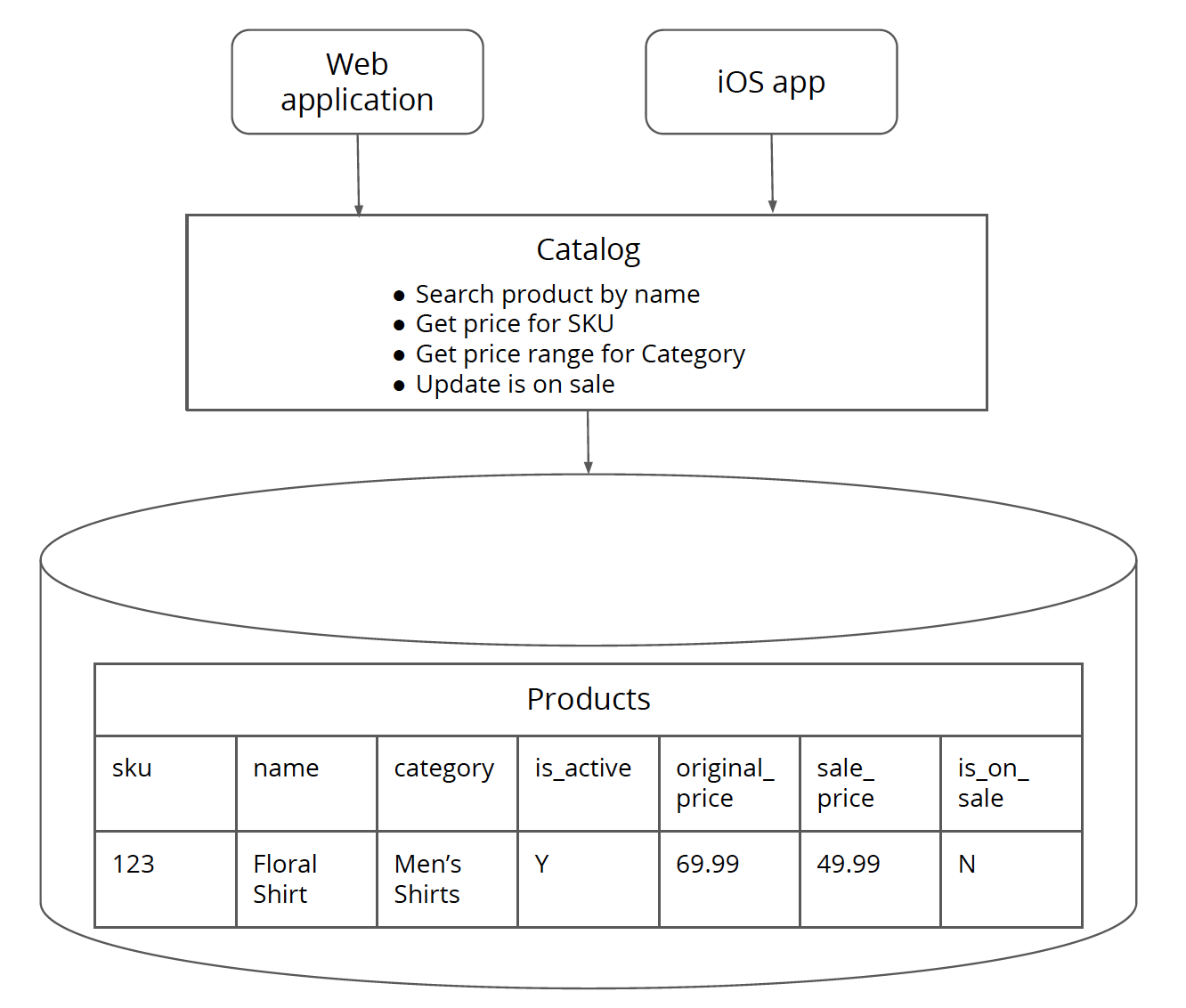
第一步 识别与新服务相关的逻辑和数据
将原服务中与价格有关的逻辑和数据识别出来:
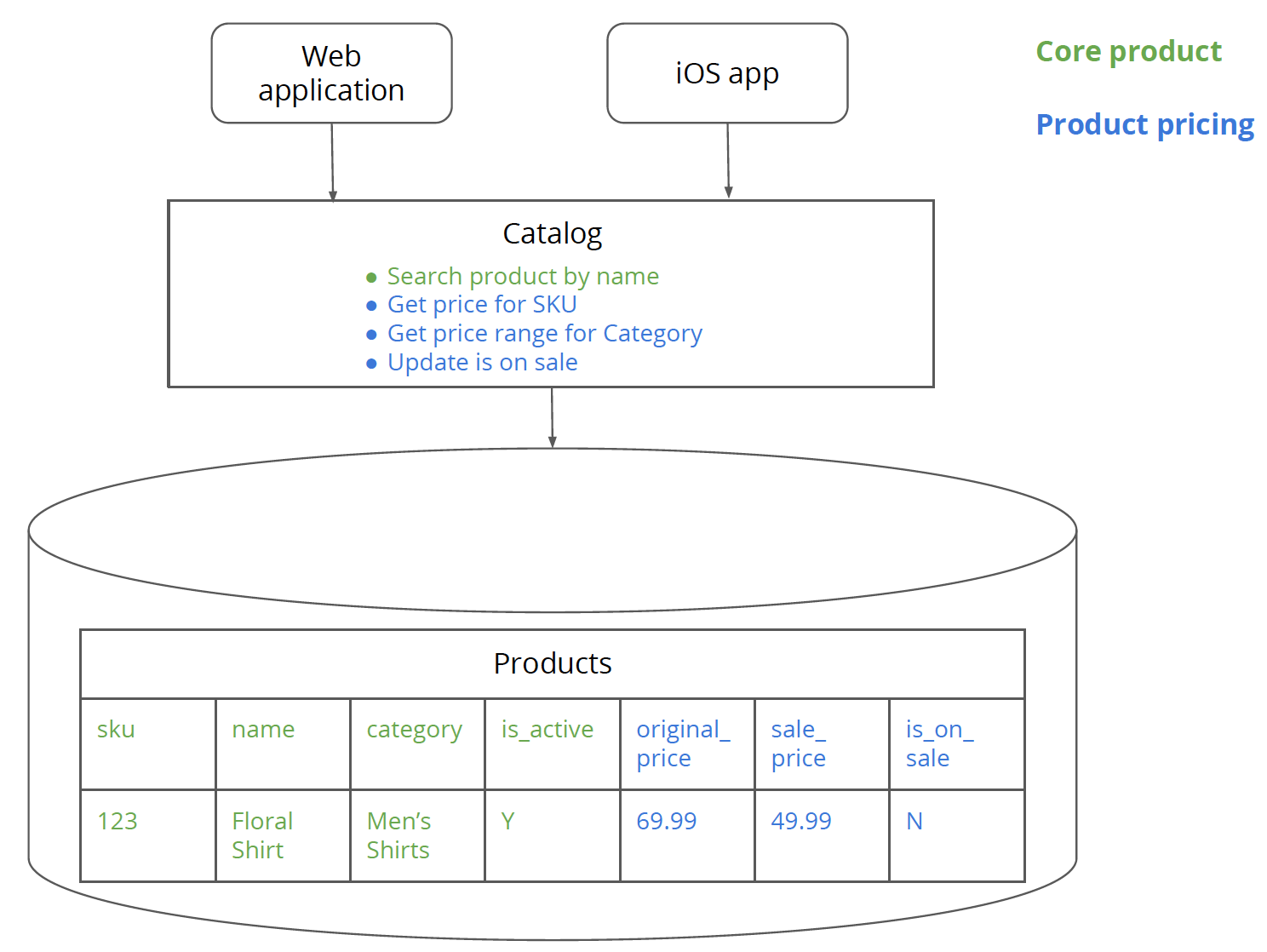
蓝色是与价格有关的逻辑和数据。
第二步 为单体架构中的新服务的逻辑创建逻辑分离
第二步和第三步是关于为产品定价服务创建逻辑和数据的逻辑分离,同时仍然在单体架构中。将CatalogService类中的逻辑分解到ProductPricingService和CoreProductService两个服务中去,其中ProductPricingService包含产品定价的相关逻辑和数据访问,CoreProductService包含产品核心的相关逻辑和数据访问,需要注意的是ProductPricingService不能直接访问核心产品的相关数据。
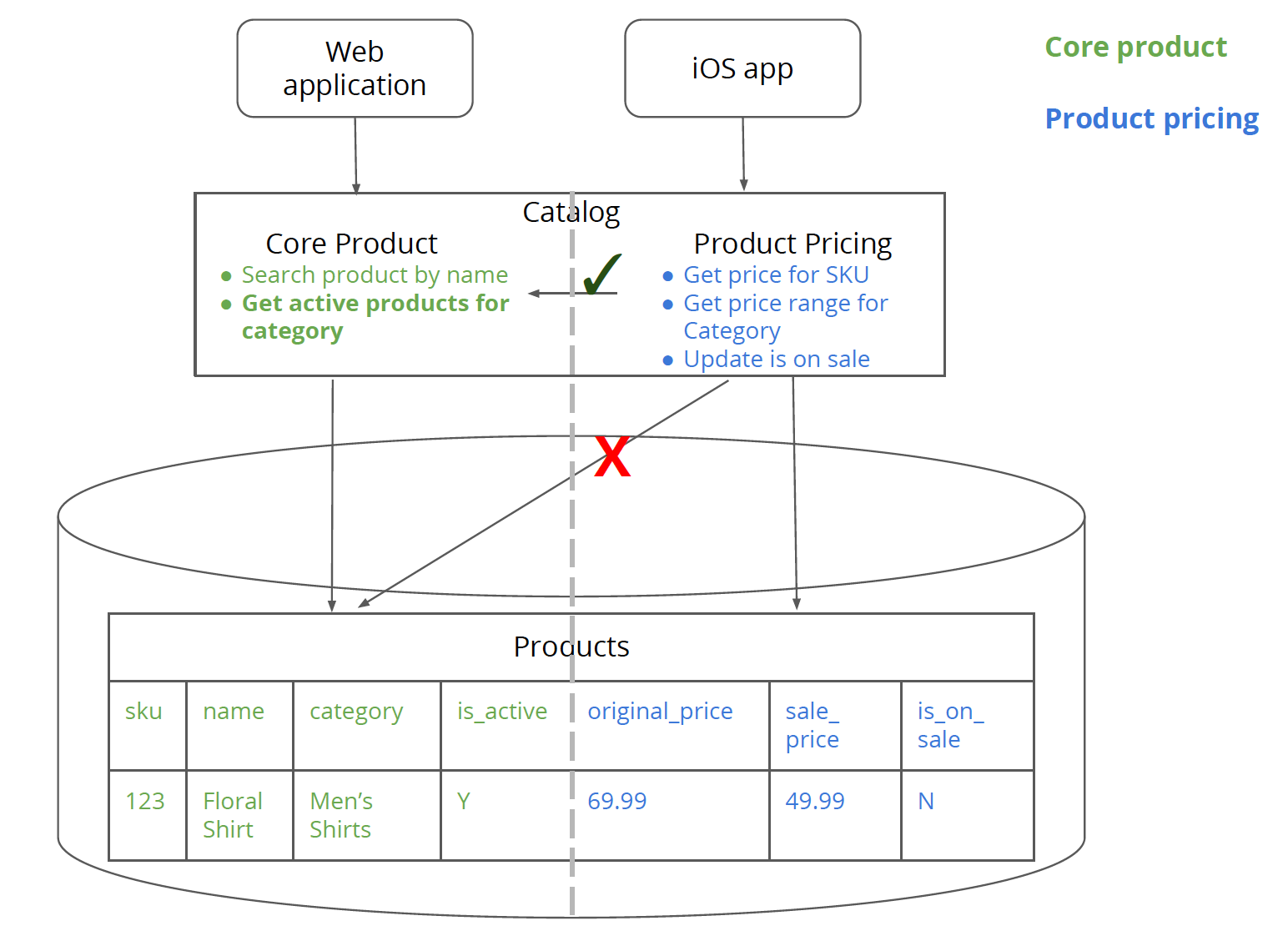
第三步 创建新表以支持单体架构中新服务的逻辑
将Products表中的价格字段和数据移入到新创建的ProductPrices表中去。需要注意的是保持字段的一致性,这会使得数据库代码变化尽可能小,符合小步原则。数据迁移也会更加容易,迁移完数据即可删除Products中的价格字段。
另外第三步还是对服务性能进行评估的好时机,如果内部的逻辑调用分离都无法达到性能要求的话,物理分离后性能只会更差。
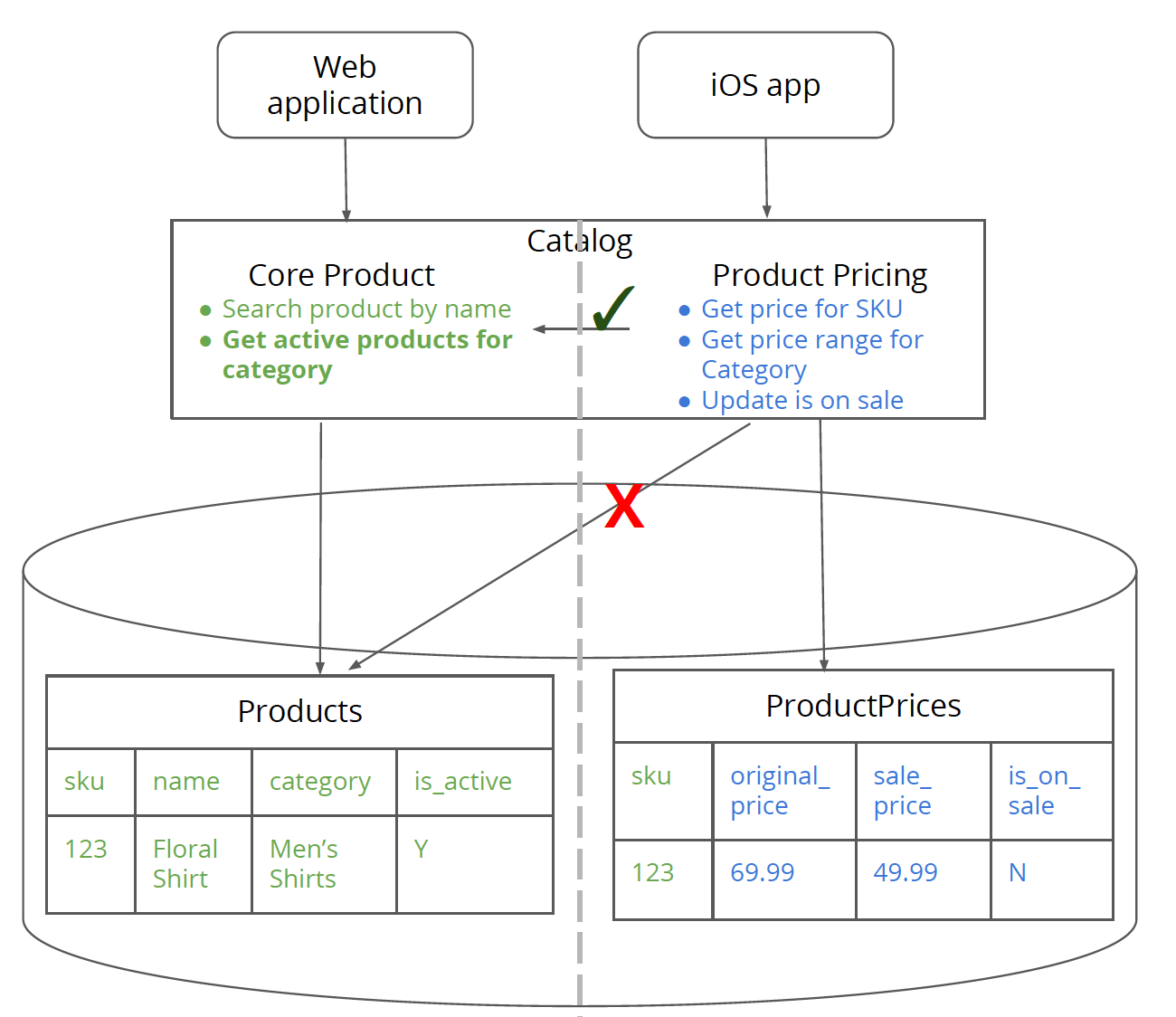
第四步 构建新服务指向单体架构数据库中的表
从第四步开始进行物理分离。构建一个新定价服务,将该服务的数据指向Catalog服务的数据库中的ProductPrices表。另外对CoreProductService的访问也将通过网络方式。
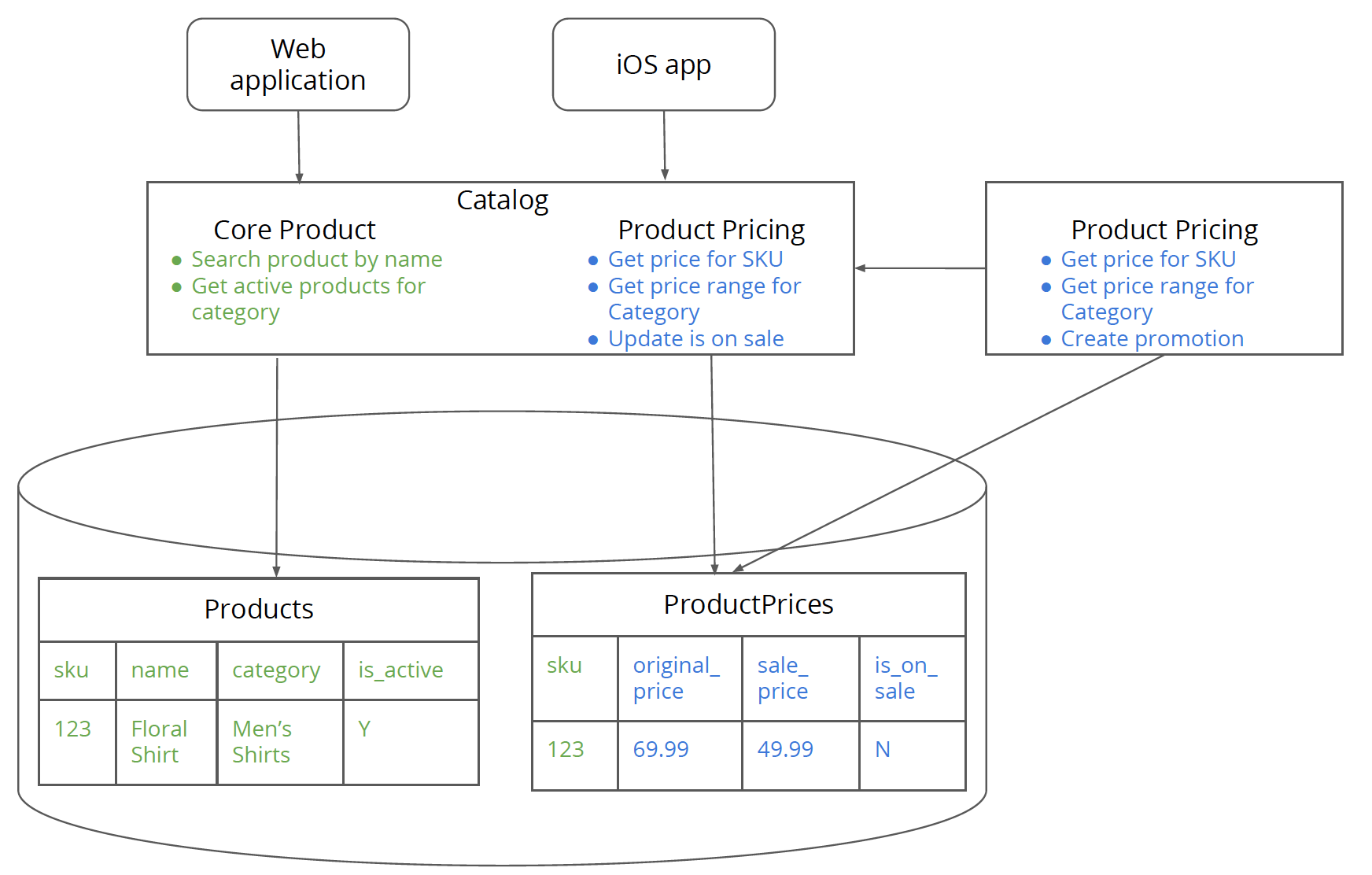
第五步 将客户端指向新服务
该步骤取决于两件事情:首先,取决于单体和新服务之间的接口有多少变化。其次,从组织的角度来看可能更复杂,客户团队必须及时完成此步骤的带宽(容量)。
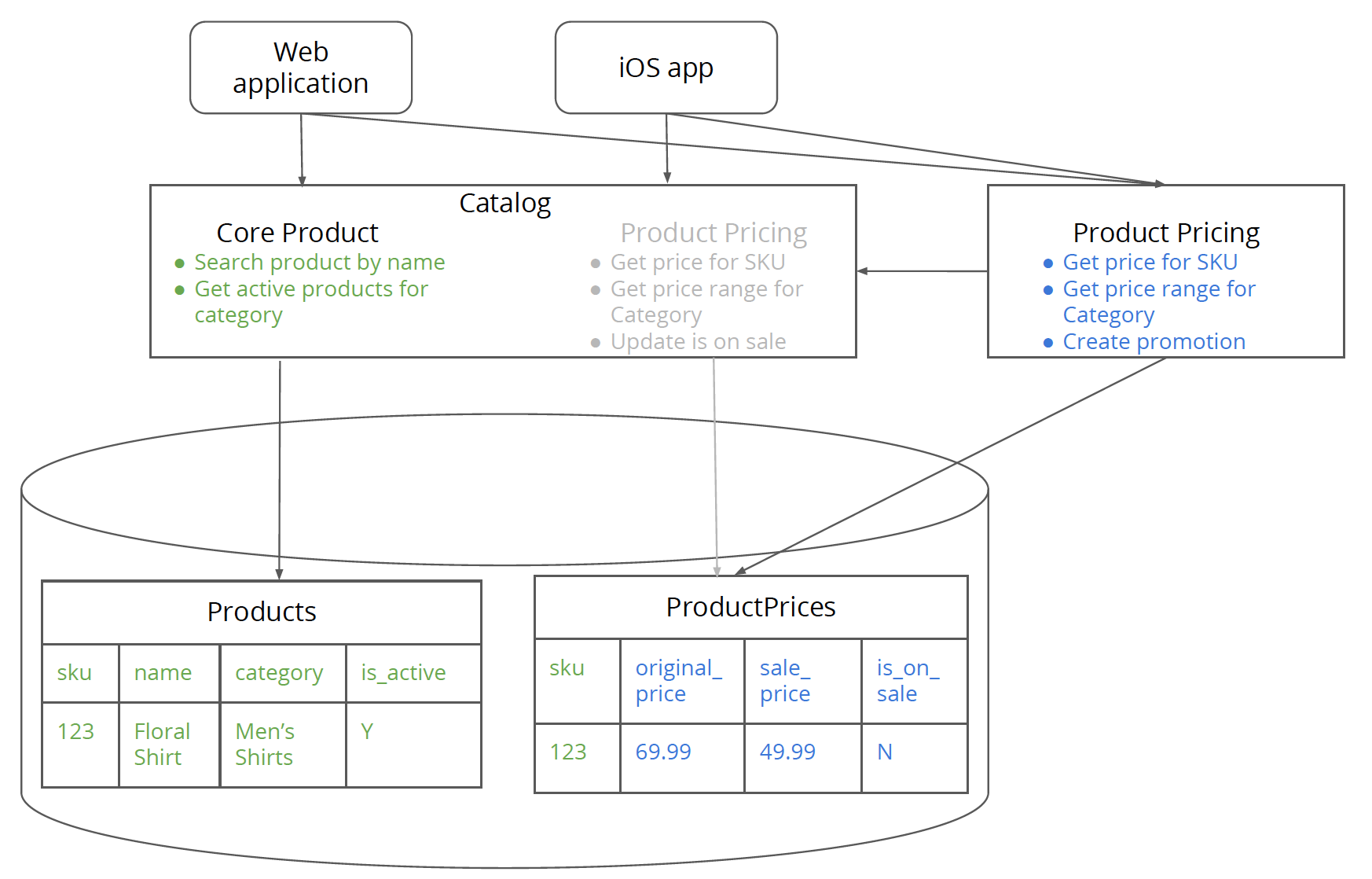
第六步 为新服务创建数据库
首先提取定价服务(完成此处提到的所有步骤),然后重构定价服务的内部实现。 一旦定价数据库被隔离,更改数据应该与更改服务中的任何代码一样,因为没有客户端会直接访问定价数据库。
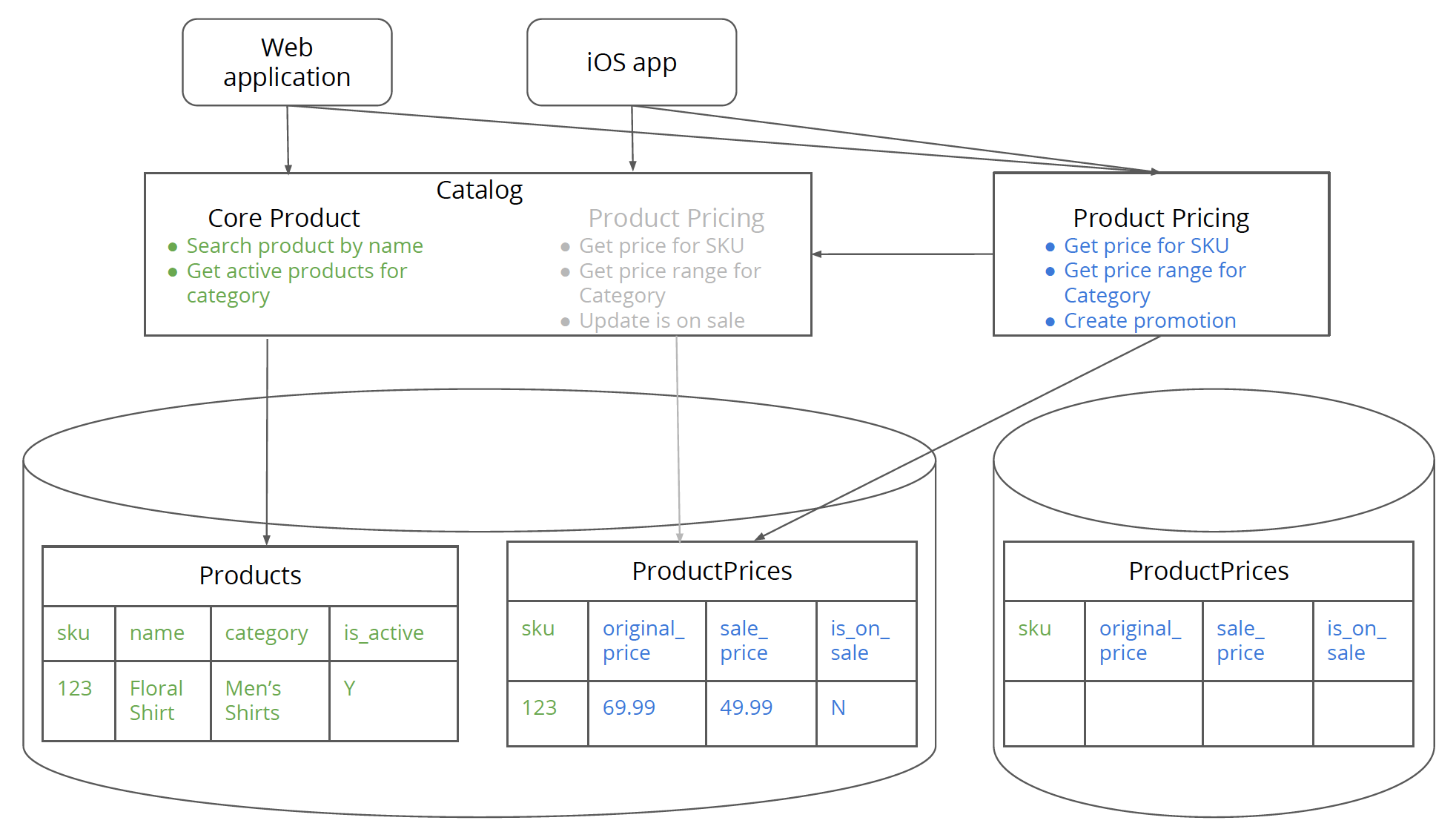
第七步 将单体架构中的数据同步到新数据库
如果schema没有改变的话,则与将定价数据库设置为单体架构的数据库的“只读副本”基本相同(尽管只是针对定价相关表)。 这将确保新定价数据库中的数据是最新的。
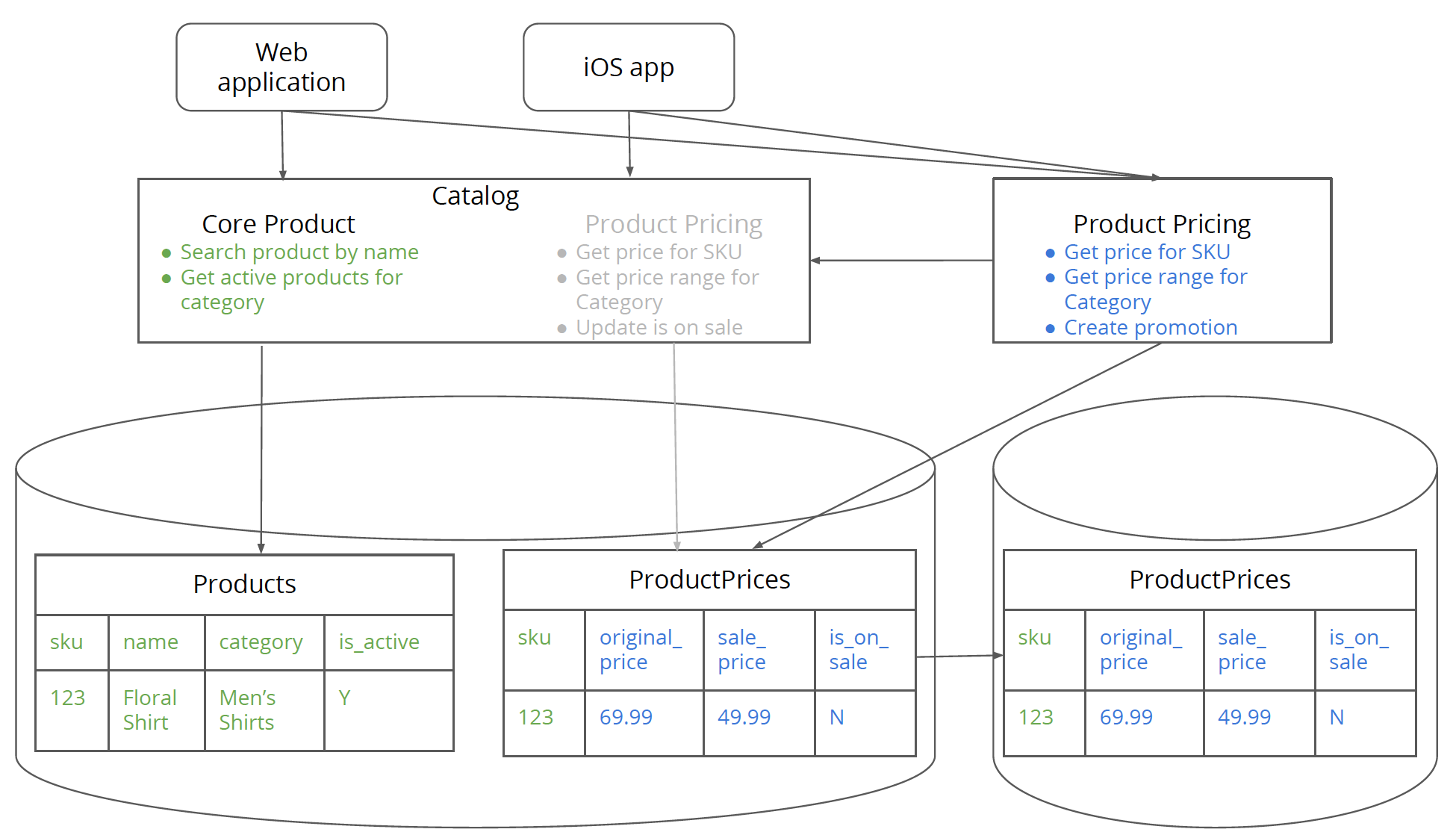
需要注意的是一个写入源,防止写冲突。
第八步 将新服务指向新数据库
在步骤如果有问题可将数据库切换回老数据库。可能遇到的一个问题是新服务中的代码依赖于新数据库中不存在但仅存在于旧数据库中的某些表/字段。 这可能是步骤1中未能识别该数据。

第九步 在单体架构中删除与新服务相关的逻辑和schema
在删除前可以做一些数据备份。
CatalogService正在执行的所有操作都是将核心产品方法调用委托给CoreProductService,因此可以删除间接层并让客户端直接调用CoreProductService。

Tip
python编程中的EAFP和LBYL风格选择tips。
What?
“Easier to Ask for Forgiveness than Permission.”(请求宽恕比许可更容易)— EAFP
“Look Before You Leap”(三思而后行 )— LBYL
Where?
EAFP(操作前不检查,出了问题由异常处理来处理)代码表现:try…except…
LBYL(操作前先检查,再执行)代码表现:if…else…
Which?
- 如果有潜在不可控的问题,使用 EAFP
- 如果预先检查成本很高,请使用 EAFP
- 如果您希望操作在大多数时间成功,请使用 EAFP
- 如果您预计操作失败的时间超过一半,请使用 LBYL
- 如果速度不重要,使用您认为更易读的风格
业务上的代码,倾向于使用 LBYL 风格。
Python 的动态类型(duck typing)决定了 EAFP,而 Java等强类型(strong typing)决定了 LBYL。
Share
概览
反模式:
- 签入不够频繁,这会导致集成被延迟
- 破碎的构建,这使团队无法转而执行其他任务
- 反馈太少,这使开发人员无法采取纠正措施
- 接收 垃圾反馈,这使开发人员忽视反馈消息
- 所拥有的 机器缓慢,这导致延迟反馈
- 依赖于 膨胀的构建,这会降低反馈速度
解决办法:
- 经常提交代码,可以防止集成变得复杂。
- 在提交源代码之前运行私有构建,可以避免许多破碎的构建。
- 使用各种反馈机制避免开发人员忽视构建状态信息。
- 有针对性地向可以采取措施的人发送反馈,这是将构建问题通知团队成员的好方法。
- 花费额外资金购买更强大的构建机器,从而加快向团队成员提供反馈的速度。
- 创建构建管道来缓解构建膨胀。
其他一些反模式:
- 持续忽视(Continuous Ignorance),也就是构建过程只包含很少的过程,导致构建总是成功。
- 构建 只在您的机器上执行,这会延长引入缺陷和纠正缺陷之间的时间。
- 瓶颈提交(Bottleneck Commits),这会导致破碎的构建,让团队成员无法回家。
- 运行 间歇构建(intermittent build),这使反馈延迟。
签入不够频繁,这会导致集成被延迟
名称:签入不够频繁
反模式:由于所需的修改太多,源代码长时间签出存储库。
解决方案:频繁地提交比较小的代码块。
破碎的构建,这使团队无法转而执行其他任务
名称:破碎的构建
反模式:构建长时间破碎,导致开发人员无法签出可运行的代码。
解决方案:在构建破碎时立即通知开发人员,并以最高优先级尽快修复破碎的构建。
用私有构建减少破碎的构建
防止破碎构建的有效技术之一是,在将代码提交到存储库之前,运行 私有构建(private build)。执行私有构建的步骤如下:
- 从存储库签出代码。
- 在本地修改代码。
- 用存储库执行更新,从而集成其他开发人员所做的修改。
- 运行本地构建。
- 构建成功之后,将修改提交到存储库。
反馈太少,这使开发人员无法采取纠正措施
名称:反馈太少
反模式:团队没有把构建状态通知发送给团队成员;因此,开发人员不知道构建已失败。
解决方案:使用各种反馈机制解决方案:使用各种反馈机制传播构建状态信息。
反馈方式:
- Ambient Orb
- RSS feed
- 任务栏监视器,比如 CCTray(用于 CruiseControl)
- X10 设备(比如 LavaLamps)
- 通过 Jabber 等发送的即时消息
- SMS(Text Messages)
警告:需要在信息过多和信息过少之间找到一个平衡点。
接收 垃圾反馈,这使开发人员忽视反馈消息
名称:垃圾反馈
反模式:团队成员很快被构建状态消息淹没(成功、失败或界于这两者之间的各种消息),所以开始忽视这些消息。
解决方案:反馈要目标明确,使人们不会收到无关的信息。
反馈太少 和 垃圾反馈是两个极端,要在它们之间找到一个适当的平衡点。 当构建破碎时,必须及时地将反馈发送给适当的人,而且必须提供采取纠正措施所需的信息。 如果构建是成功的,那么应该只向少数人发送反馈,包括最近提交修改的开发人员以及希望掌握最新情况的技术领导。
所拥有的 机器缓慢,这导致延迟反馈
名称:缓慢的机器
反模式:用一台资源有限的工作站执行构建,导致构建时间太长。
解决方案:增加构建机器的磁盘速度、处理器和 RAM 资源,从而提高构建速度。
如果发现构建机器在速度、内存或硬盘方面无法让人满意,就应该认真考虑进行升级;加快构建可以帮助我们更快地获得反馈,快速纠正问题,更快地转到下一个开发任务。
依赖于 膨胀的构建,这会降低反馈速度
名称:膨胀的构建
反模式:把太多的任务添加到提交构建过程中,比如运行各种自动检查工具或运行负载测试,从而导致反馈被延迟。
解决方案:一个构建 管道(pipeline)可以运行不同类型的构建。
为了向团队成员提供更多的构建信息,团队往往会逐渐增加构建过程的内容。要向开发团队提供快速反馈,还要从 CI 构建过程提供有用的信息,必须在这两个目标之间取得平衡。
创建所谓的 构建管道(build pipeline)。构建管道的用途是异步地执行长时间运行的过程,这样的话,开发人员签入代码之后,不需要长时间等待反馈。
有效的构建管道应该充分利用 “80/20” 规则:百分之 20 的构建时间花费在导致百分之 80 的构建错误(比如缺少文件、破碎的编译和测试失败)的部分上。完成这个过程之后,开发人员接到反馈,然后运行第二个构建过程,这个过程的运行时间比较长,但是只产生百分之 20 的构建错误。
参考文献
- https://martinfowler.com/articles/break-monolith-into-microservices.html
- https://martinfowler.com/articles/extract-data-rich-service.html
- https://www.ibm.com/developerworks/cn/java/j-ap11297/index.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!