
TLA+案例:JAVA缓冲区建模
前面的文章中提到,由于并发系统的不确定性,导致对系统的测试和调试是非常困难的。下面以共享缓存区为例来介绍如何在并发场景下应用TLA+。
背景介绍
假设要设计一个共享缓冲区系统,包含三块内容:生产者、消费者、缓冲区。
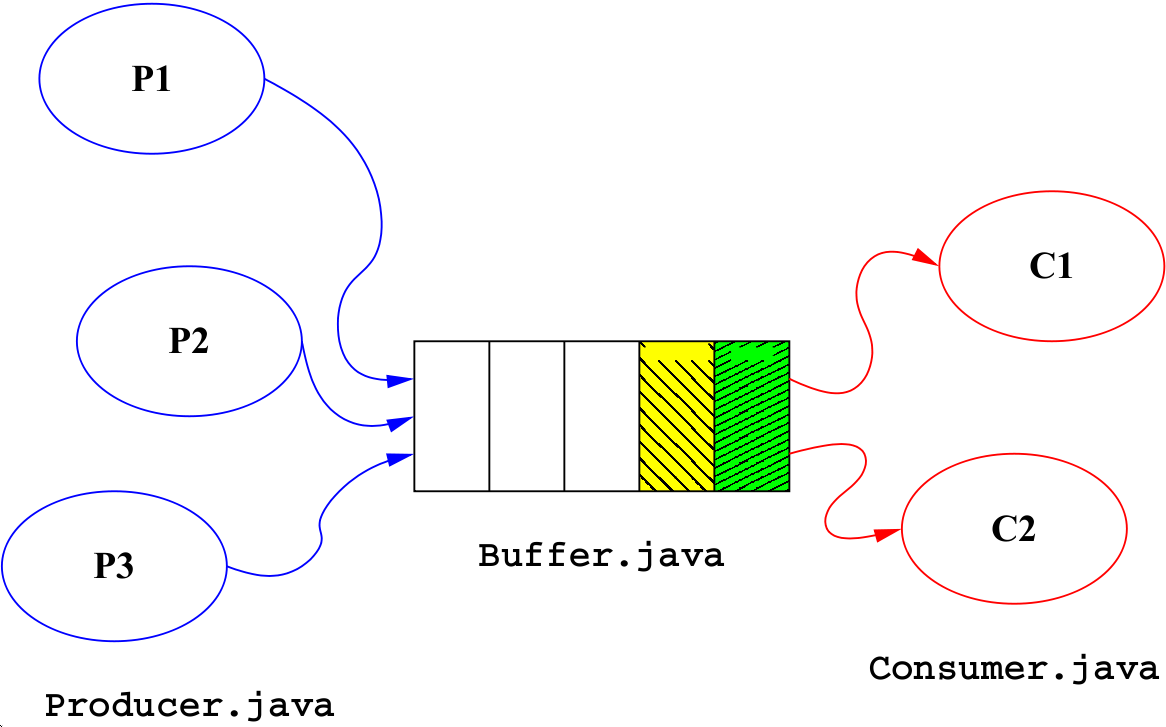
- 生产者:负责往缓冲区中写入数据。
- 消费者:负责从缓冲区中读取数据。
- 缓冲区:充当读写数据的同步器。缓冲区满的时候生产者需要等待,缓冲区空的时候消费者需要等待。
系统主要的同步控制通过缓冲区来完成,生产者和消费者只负责简单的写入和读取。由此可见缓冲区就是系统设计的关键所在,其JAVA实现如下:
public class Buffer<E> {
public final int capacity;
private final E[] store;
private int head, tail, size;
@SuppressWarnings("unchecked")
public Buffer (int capacity) {
this.capacity = capacity;
this.store = (E[])new Object[capacity];
}
private int next (int x) {
return (x + 1) % store.length;
}
public synchronized void put (E e) throws InterruptedException { // 同步写入
while (isFull()) // 满则等待
wait();
notify();
store[tail] = e;
tail = next(tail);
size++;
}
public synchronized E get () throws InterruptedException { // 同步读取
while (isEmpty()) // 空则等待
wait();
notify();
E e = store[head];
store[head] = null; // for GC
head = next(head);
size--;
return e;
}
public synchronized boolean isFull () { // 判断已满
return size == capacity;
}
public synchronized boolean isEmpty () { // 判断为空
return size == 0;
}
}
上述代码完全满足设计需求,无论在实现逻辑上,亦或可读性上都非常清晰易懂,通过代码走查应该问题不大,就这样提交到master分支,并进入了生产环境中。
问题

系统运行了一段时候后的某天深夜你被电话惊醒,被运维人员告知系统出了异常,需要马上解决。这时正式开始了痛苦且充满不确定的分布式系统调试过程。我们可能会这么干:
-
增加一些有助于调试定位的打印
public synchronized void put (E e) throws InterruptedException { String name = Thread.currentThread().getName(); while (isFull()) { logger.info(String.format("buffer full; %s waits", name)); waitSetSize++; wait(); logger.info(String.format("%s is notified", name)); } logger.info(String.format("%s successfully puts", name)); notify(); if (waitSetSize > 0) waitSetSize--; logger.fine(String.format("wait set size is %d", waitSetSize)); store[tail] = e; tail = next(tail); size++; lastChange = System.currentTimeMillis(); }ok,做好了准备工作,开始调试。
-
在实验室照搬故障现场进行测试 几个小时过后,没有出现任何问题,效率太低这时只有放弃拷机测试。 开始考虑对系统进行简化,模拟构建些生产者和消费者,来提升测试效率。
-
在实验室通过简化和模拟来测试
以模拟生产者为例子:
class Producer extends Thread { public Producer (int n) { super("producer-"+n); } public void run () { String name = getName(); try { while (true) { sleep(rand.nextInt(sleepProd)); buffer.put(name); } } catch (InterruptedException e) { return; } } }通过sleep随机时间来模拟业务过程,简化写入数据(仅写入生产者实例名称)。对于有经验的开发者,在共享资源竞争的情况下最容易出现的就是死锁问题。
long time = System.currentTimeMillis(); while (true) { Thread.sleep(60000); // check for deadlock every minute synchronized (buffer) { if (buffer.waitSetSize == threadCount) { logger.severe(String.format ("DEADLOCK after %d messages and %.1f seconds!", buffer.msgCount, (buffer.lastChange - time)/ 1e3)); for (Thread t : participants) t.interrupt(); return; } } }在主函数中定期(每分钟)检查生产者和消费者是否存在死锁问题。
-
问题发生
在不断的尝试过程中,在缓冲区容量为2,生产者数量为3,消费者数量为2的场景下,终于出现了死锁。
java AnnotatedBuffer 2 3 2 3 2 01:35:39.047: DEADLOCK after 3970423422 messages and 1576335.9 seconds!可以看下中间所经历的消息交互数量(近40亿次)和时间(大约18天)。这还是在模拟系统规模极小和业务速度极快的情况下。说不定过程中又放弃了。
当然也不是每次都会这么慢,这只是一种执行的可能性。
使用TLA+
编写Spec
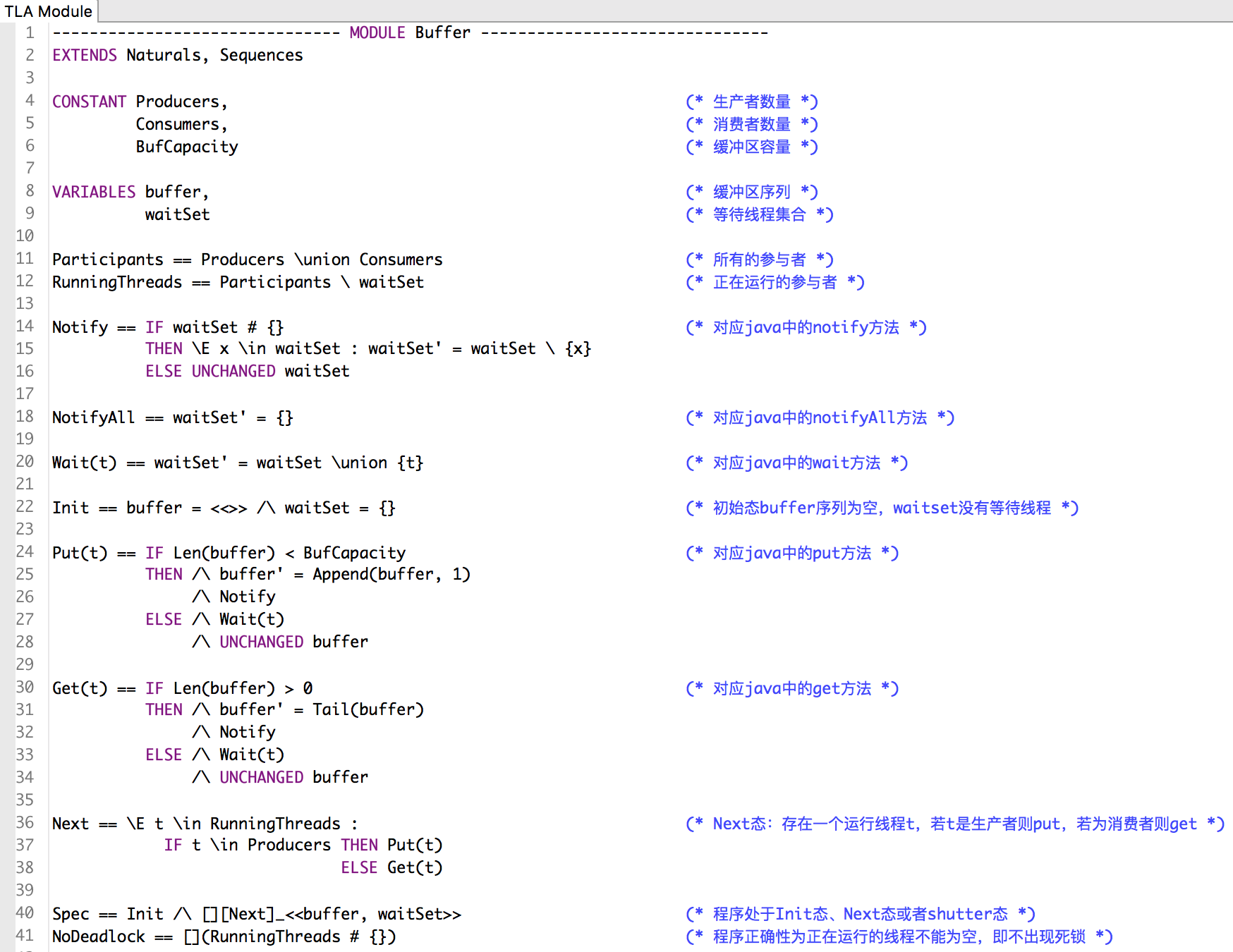
Spec中的注释已经很清晰了,下面就没有注释的内容进行解释:
- NEXT表达存在一个运行的线程,若该线程为生产者则随机选取一个存在于Data的m,并将其put到buffer。若该线程为消费者则从buffer中get一个数据。
- Prog就是前面所介绍的时态逻辑格式
- 最后一行的THEORREM表示Prog蕴含一直满足类型不变式和非死锁性。
模型设置
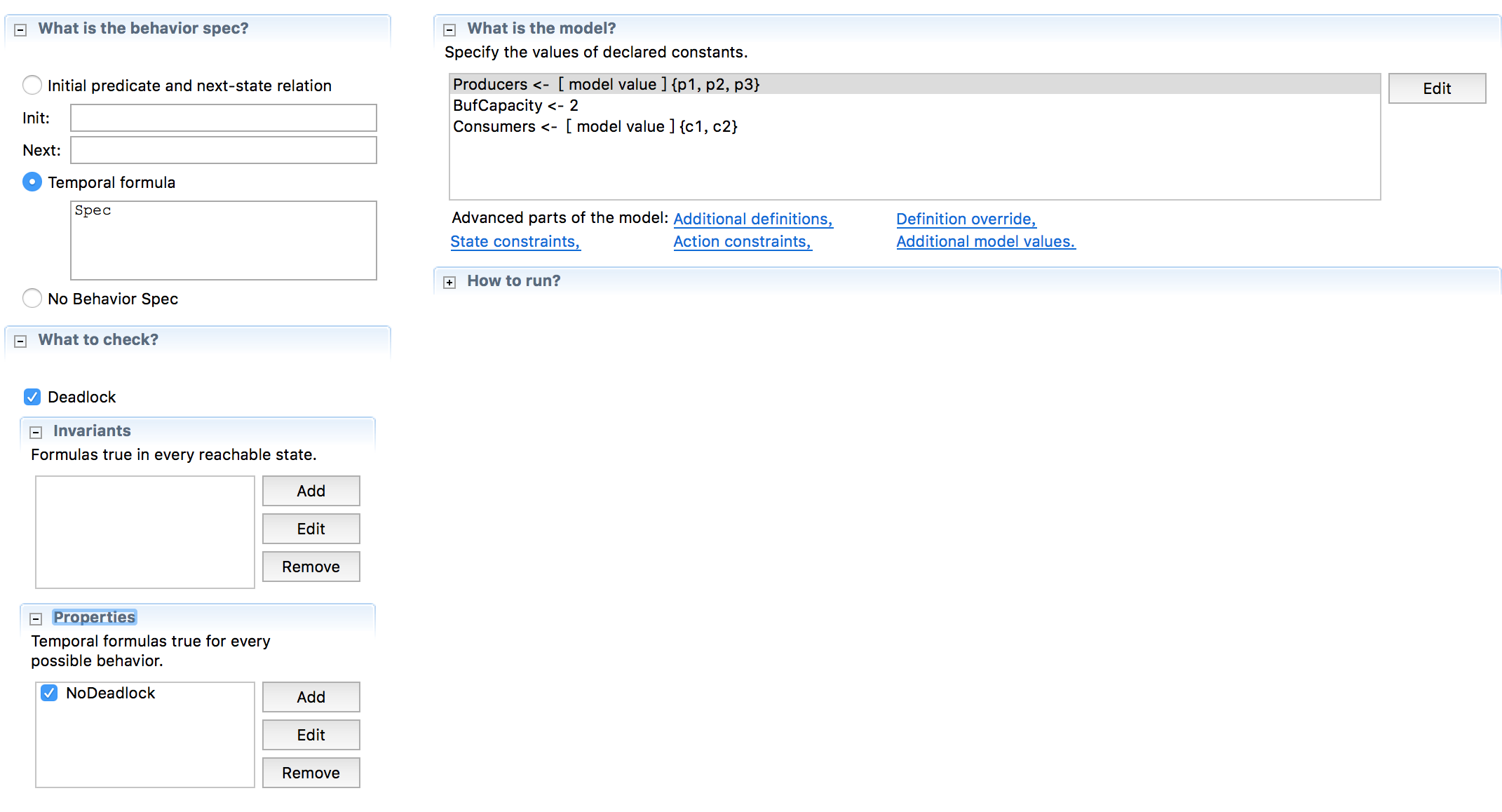
主要设置了四块内容:
- 勾选Deadlock(默认就是勾选的,适用于并发系统验证)。
- 时态公式Prog配置。
- NoDeadlock属性配置。
- 一些常量配置。
执行TLC
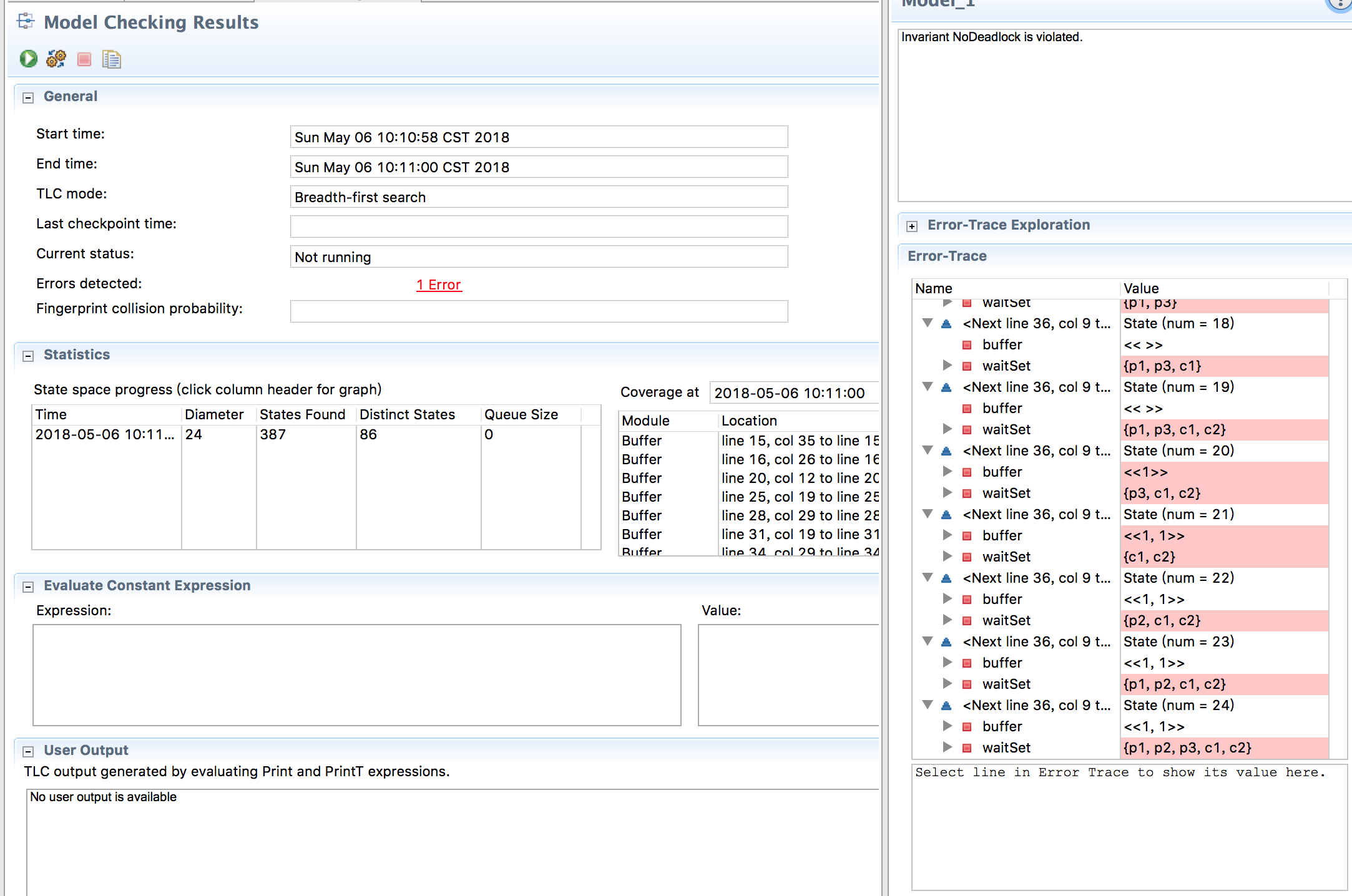
点击执行按钮后,很快就检查出了不变量NoDeadlock冲突,右下角Error-Trace窗口展示的就是该冲突所出现的过程。总共经过24步waitSet就包含了全部线程,你可以通过trace清楚的了解到错误发生的整个过程。整个系统涵盖的总状态数量为387。
感兴趣的读者可以将生产者设置为{p1,p2},然后再运行TLC,你会发现TLC检测通过了。
减少了一个生产者整个问题的状态成指数级下降。结果正确证明了系统是否异常跟buffer的设计关系也没有那么密切,而跟资源如何规划关系更紧密。通过泛化可以推导出以下结论:
2 * BufCapacity >= Producers + Consumers
疑问
问题:在内部培训时,有同学提出Spec的编写成本跟真实的buffer.java差不多,建模的性价比是否太低?
解答:其实这个问题得这样看当完成TLA+的spec和模型配置后,相当于实现了整个buffer系统(包括:生产者、消费者以及缓冲区)而非仅仅实现了buffer.java类。以较小的成本实现原型系统和对系统的全面状态检查才是TLA+的强大之处。
参考文献
http://www.cs.unh.edu/~charpov/teaching-cs745_845-example.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!