
【译】拥抱SOA网络的数据一致性
本文是我给service mesh社区翻译的一篇文章,原文地址
Envoy的基本设计原则之一是最终的一致性,几乎渗透到系统的每个方面,从线程模型到服务和配置发现(参见这里和这里以获得更多信息)。
我注意到在过去的几年中,当强如最终一致性的范式应用于SoA网络时,许多人发觉它是反常识的。 这并不奇怪:最终的一致性在理论上是有道理的,但是当实际应用于许多现实世界的问题中时则很容易出现混乱。
试图平衡最终一致性的性能收益与强一致性对程序员的易用性的当代数据库设计就是一个很好的例子。 业界已经看到应用趋势从强一致的事务性RDBMS(如MySQL)转向最终一致的NoSQL系统(如DynamoDB),转而回到可扩展的一致性事务性RDBMS(如:Google的Spanner)。 关于为什么程序员应该总是选择强一致性,这个文章是可以很好的理解这个问题。 (顺便说一句,我认为Cloud Spanner是一个绝对改变游戏规则的技术,但这不是本文的主题。)
在这篇文章中,我将讨论为什么在SoA网络中拥抱最终的一致性是如此重要。 我还将解释一些分布式系统程序员需要重新考虑如何评估和使用最终一致的服务发现和负载平衡系统以获取全部价值的方式。
最终一致性的缘由
从根本上说,分布式系统的核心是最终一致的:
- 计算节点随时可能死亡或暂时失去连接。
- 网络路径可能会死亡或暂时中断,导致路由更改并可能出现脑裂的情况。
- 无论是由于滚动部署,金丝雀,cron抖动还是许多其他因素,软件部署都不会同时发生。
- 自动缩放通过设计来频繁更改系统拓扑。 节点不会同时关闭,也不会同时启动。 随着行业越来越趋向FaaS,这个事实只会变得更加明显。
另请参阅Werner Vogels撰写的关于深入讨论计算机科学的最终一致性的文章。
当然,可以在最终一致的基础之上分一个强一致性层; Spanner是一个工程奇迹,就是这样做的。 然而,领导选举,法定人数,共识算法等在工程和运营复杂性方面都有成本,更重要的是增加了延迟。 保证强一致性不是免费的。 对Spanner的读写操作时长可能比应用于最终一致的NoSQL系统要多一个数量级。
回到Envoy和基于SoA的网络和配置发现,对于在数万,数十万甚至数百万个节点中的每一个节点都可能具有一致的全系统的视图吗? 我不会辩驳。 然而历史上许多分布式网络系统依靠强一致存储(例如,ZooKeeper)来保存成员资格和软件版本数据。 将这些存储扩展到大数据量是困难的并且会经常导致当机。 那为什么要这么麻烦呢?
当最初设计Envoy时,我的目标是拥抱核心分布式网络的最终一致性,并将其推向其逻辑极端:
- 如果成员数据不一致,为什么我们不能在每个发现服务节点的内存中缓存数十秒?
- 如果在每个发现服务节点中成员数据被缓存了几十秒,为什么每个envoy不能缓存几十秒呢?
- 如果每个envoy缓存数据达数十秒,为什么每个工作线程中都需要envoy的一致性? (有关这方面的更多信息,请参阅Envoy的线程模型的文章。)
答案是当涉及分布式网络的成员资格和配置时,不需要在任何地方保持一致性(因为在任何地方都不可能有一致性)。 拥抱最终的一致性的地方会产生一个更简单,性能更高,更容易操作的系统。
一致性和envoy的xDS API
我不会在本文中再介绍Envoy API。 相关完整的介绍请参阅我对通用数据平面API和Envoy动态配置的文章。
我将谈到由于编程的简单性和性能的原因,所有的envoy API都是最终一致且不相同的,即便他们可能在逻辑上相关。 例如,路由发现服务(RDS)API提供的路由可以引用由集群发现服务(CDS)API提供服务的集群。 但RDS并不明确依赖于CDS。 这意味着如果Envoy连接到RDS API和CDS API的不同管理服务器,则可能很容易向Envoy发送一个尚未被CDS API的管理服务器定义的群集的路由更新。
前面的内容正是许多新用户对Envoy配置和发现模型感到困惑的原因。 他们会问如果API是相关的,但最终是一致的且分离的API,会不会导致envoy出错呢? 从技术上讲,事实上最终一致的API消费的可能会导致诸如前面所述的路由到尚不存在的集群的情况。 但这种情况是否会在现实世界真实发生呢?
如何在现实世界中应用分布式负载平衡和路由配置?
最近我最感兴趣的事情之一就是观察人们如何评价envoy和Istio这样的系统。 从“踢轮胎”的简单的测试开始是人的本性。初始用户可能立即做两件事情:
- 执行某种类型的“赛马”的基准测试,将envoy与HAProxy,NGINX或其他一些负载均衡器进行比较(例如:查看是否可以按每个CPU线程来推送25K + RPS的合成HTTP流量)。
- 与Kubernetes一起使用Istio或为Envoy编写一个简单的xDS服务器,然后使用RDS和CDS执行小型测试来将流量立即从群集A转移到全新的群集B.
我不会花很多时间讨论事情1。 我理解新用户这样做的原因,但这让我感到沮丧。因为这些基准在确定真实世界效能方面非常不切实际(您最后一次在真实系统中每次执行25K RPS每线程琐碎请求和响应的时间是何时?)。 性能是非常重要的,但是真实世界的性能是非常复杂的且它基于P99的系统功能和实际工作负载的性能。 这些现实主要决定了需要多少容量余量来满足使用突发。
上面的事件2更有意思。
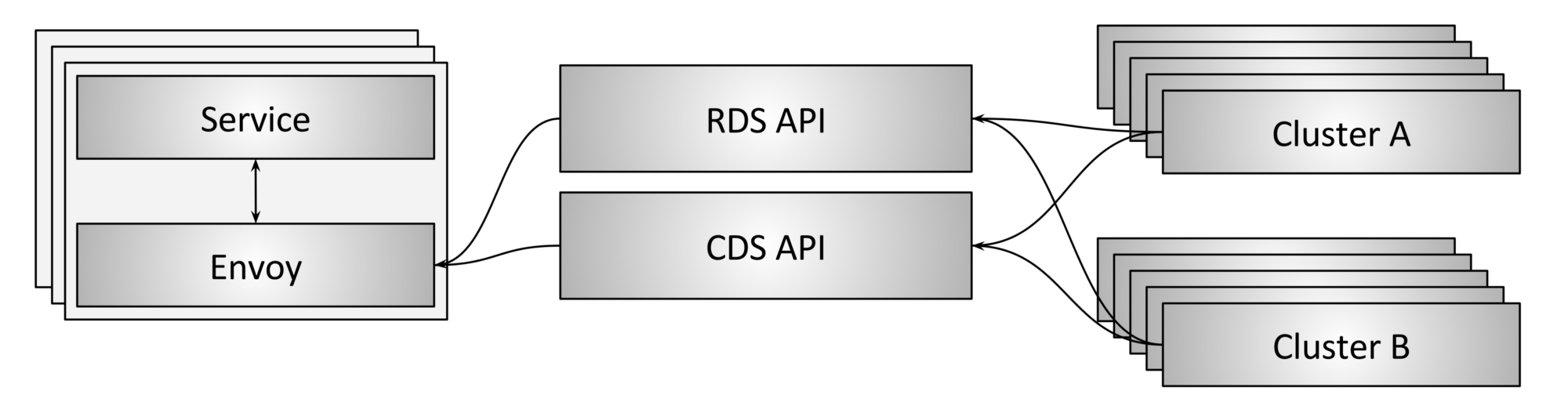
图1示出了上述事件2的图形描述。 在这种情况下,RDS提供路由信息,而CDS提供静态集群信息(真实实现可能还会使用端点发现服务API,为了不让此示例更复杂没有考虑)。 假设以下一系列事件:
- CDS提供了集群A的静态端点定义
- RDS提供路由映射到集群A.
- 运维人员进行更改,立即让CDS提供集群B,同时删除集群A,并让RDS提供路由映射到集群B.
在使用Envoy最终一致的模式时,在这种情况下会发生什么? envoy很可能会有一段时间在服务404或503(取决于配置)。 这是由于系统中的每个组件最终都会收敛。 这意味着,以不确定的顺序,特使最终将删除集群A并将其替换为集群B,并最终将替换从集群A到集群B的路由映射。在收敛的中间阶段,映射可能是无效的,导致错误响应。
这难道不是一个错误? 大多数用户原有经验都是这样认为的。 事实上,由于用户的这种第一反应非常普遍,大多数产品也将其视为一个bug,即便这在任何设计良好的分布式系统运行期间都不会真正发生。
在现实世界中,大概会发生如下的一系列事件:
- 集群B可以手动创建,也可以通过自动蓝/绿色部署的过程创建。
- 通过手动或自动测试以确保集群B已启动并准备好接收流量。
- 流量从集群A缓慢地转移到集群B,开始通过金丝雀的方式,最后通过百分比展开(因此集群A,集群B和指向它们的路由都同时存在)。
- 当没有更多的流量进入集群A时,集群A和相关路由最终被删除。
请注意这一系列事件中,Envoy流量切分API的最终一致模型不会产生副作用。 尽管底层的实现以非确定性的方式收敛,系统用户最终还是会观察到他们所期望的行为。
Envoy聚合发现服务(ADS)API

因为大多数用户在开始使用Envoy和控制平面(例如Istio)时都会执行的初始人工路由测试,且大多数用户认为他们所看到的情况是错误的,基于Envoy构建的产品通常比Envoy API原生提供的一致性更高。 这是产品设计权衡的一个很好的例子。 由于执行不切实际的“踢轮胎”测试时的用户第一反应非常消极,有时产品必须提供完全不会在现实世界中使用的行为。
为此,我们开发了聚合发现服务(ADS)API。 如图2所示,该API允许所有其他的Envoy API在单个gRPC流上进行复用,从而确保单个管理服务器处理所有这些API。 这允许管理服务器按照Envoy永不丢弃任何请求的方式对发现更新进行排序。 也就是说在上述案例,管理服务器可强制实施这样一个事实,即集群B被添加,/被指向集群B,然后集群A被删除,全部按照特定的顺序。
但在计算中并没有免费的午餐。 基于ADS的管理服务器的开发要比使用分离的RDS,CDS,EDS等API的完全最终一致的实现复杂得多。 并且需要重申且非常讽刺的是:ADS实施所带来的所有复杂性,主要是为满足用户执行一系列在现实世界中不会发生的人工测试的最初反应。
结论
分布式系统设计通常是最终与强一致组件的复杂折衷。 最终一致性通常会产生更好的性能、更简单的操作和更好的可伸缩性,同时要求程序员理解更复杂的数据模型。
系统设计潮流也是随时间而改变的。 正如我在介绍中所描述的那样,数据库行业在多年以来都倾向于在最终一致的存储上构建应用并也已意识到它的复杂性,当代数据库则倾向于转回强一致性。
另一方面,我相信SoA网络一直是最终的一致,否则就是自欺欺人。 相反,我们应该拥抱最终一致的分布式网络模型。 拥抱最终一致性的部分内容是评估系统在生产中的使用方式,而非如何快速进行一些的测试。 我是一个现实主义者; 我不认为这种改变会在一夜之间发生,但鉴于ADS的存在以及将由一些管理服务器和产品来实现纯粹是为了满足我认为是不切实际的用例,意味着我们还有很长的路要走。
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!